Уважаемые пользователи!
«Персональный менеджер» запустил востребованную услугу – аудит контекстной рекламы. Мы поможем улучшить вашу текущую рекламную кампанию или эффективно настроить новую. Аудит предполагает работу с семантическим ядром, объявлениями, стратегией и непосредственно с самим сайтом. Всего за 3000 рублей вы получите профессиональный консалтинг и рекомендации, что позволит сэкономить рекламный бюджет и повысить эффективность продвижения.
Присылайте заявки из списка ваших проектов в Системе.
С уважением, Юлия Бородина, руководитель клиентской службы
Технологии поискового маркетинга
Дубли контента – это частично или полностью одинаковый текст, картинки и прочие элементы наполнения сайта, доступные по разным адресам страниц (URL). Наличие дублей может значительно затруднять поисковое продвижение сайта.
По оценке специалистов, дублированный контент – самая распространенная ошибка внутренней оптимизации, присутствующая на каждом втором веб-ресурсе.
Как проверить, есть ли дубли на вашем сайте, и каким образом от них избавиться? Об этом мы расскажем в новом выпуске нашей рассылки.
Какие бывают дубли
Дубли бывают четкие и нечеткие (или полные и неполные).
Четкие дубли – страницы-копии с абсолютно одинаковым контентом, содержимым мета-тега Description и заголовка Title, доступные по разным адресам. Например, у исходной страницы могут появиться следующие дубли:
- зеркало с WWW или без;
- страницы с разными расширениями (.html, .htm, index.php, GET-параметром «?a=b» и т. д.);
- версия для печати;
- версия для RSS;
- прежняя форма URL после смены движка;
- и так далее.
Нечеткие дубли – частично одинаковый контент на разных URL.
В качестве примеров таких дублей можно привести следующие варианты:
- карточки однотипных товаров с повторяющимся или отсутствующим описанием;
- анонсы статей, новостей, товаров в разных рубриках, на страницах тегов и постраничной разбивки;
- архивы дат в блогах;
- страницы, где сквозные блоки по объему превосходят основной контент;
- страницы с разными текстами, но идентичными Title и Description.
Чем опасны дубли для продвижения
1. Затрудняется индексация сайта (и определение основной страницы)
Из-за дублей количество страниц в базе поисковых систем может увеличиться в несколько раз, некоторые страницы могут быть не проиндексированы, т. к. на обход сайта поисковому роботу выделяется фиксированная квота количества страниц.
Усложняется определение основной страницы, которая попадет в поисковую выдачу: выбор робота может не совпасть с выбором вебмастера.
2. Основная страница в выдаче может замениться дублем
Если дубль будет получать хороший трафик и поведенческие метрики, то при очередном апдейте он может заменять основную (продвигаемую) страницу в выдаче. При этом позиции в поиске «просядут», т.к. дубль не будет иметь ссылочной популярности.
3. Потеря внешних ссылок на основную страницу
Желающие поделиться ссылкой на сайт могут ошибочно ссылаться на страницы-дубли. Ссылочный вес будет «размазан» между страницами, и ситуация с определением наиболее релевантной версии усугубится.
4. Риск попадания под фильтр ПС
И Яндекс, и Google борются с неуникальным контентом, в связи с чем могут применить к «засоренному» сайту фильтры АГС и Panda.
5. Потеря значимых страниц в индексе
Неполные дубли (страницы категорий, новости, карточки товаров и т. д.) из-за малой уникальности имеют шанс не попасть в индекс поисковиков вообще. Например, это может случиться с частью товарных карточек, которые поисковый алгоритм сочтет дублями.
Как найти и устранить дубли на сайте
Будучи владельцем сайта, даже без специальных знаний и навыков вы сможете самостоятельно найти дубли на вашем ресурсе. Ниже дана инструкция по поиску и устранению дублированного контента.
Поиск полных дублей
Самый быстрый способ найти полные дубли на сайте – отследить совпадение тегов Title и Description. Для этого можно использовать панель вебмастера Google или популярный у оптимизаторов сервис Xenu. Поиск ведется среди проиндексированных страниц.
1. Ищем с помощью Google Search Console
Показать подробности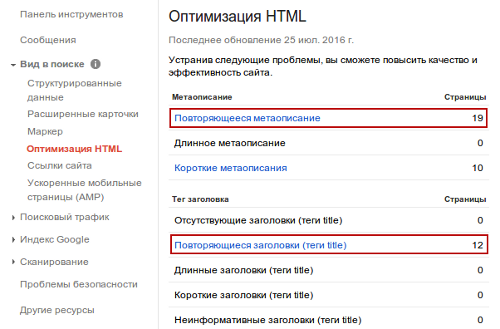
2. Ищем с помощью программы Xenu
Показать подробности3. Ищем в адресной строке браузера
Показать подробностиУстранение полных дублей
Полные дубли появляются по различным причинам, поэтому для их устранения применяются разные способы.
1. 301 редирект для главной страницы
Уровень сложности: высокий
Показать подробности2. Массовый 301 редирект
Уровень сложности: профессиональный
Показать подробности3. Запрет индексации в Robots.txt
Уровень сложности: средний
Показать подробности4. Тег rel=canonical
Уровень сложности: средний
Показать подробности5. Удаление с ошибкой 404
Уровень сложности: средний
Показать подробности6. Готовые решения для популярных CMS
Уровень сложности: высокий
Показать подробности7. Борьба на уровне движка
Уровень сложности: профессиональный
Показать подробностиПоиск неполных дублей
1. Ищем при помощи вебмастера Google или сервиса Xenu
Показать подробности
2. Ищем в строке поиска Яндекса или Google
Показать подробности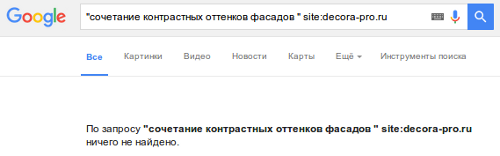
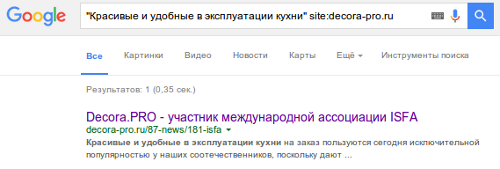
Устранение неполных дублей
1. Оптимизация мета-данных
Уровень сложности: средний
Показать подробности2. Оптимизация контента
Уровень сложности: средний
Показать подробности3. Оптимизация структуры и перелинковки
Уровень сложности: средний
Показать подробности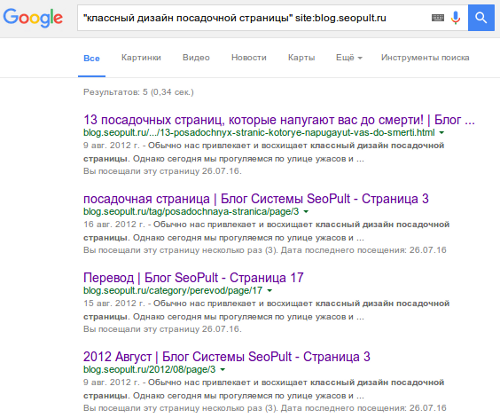
Проверяйте и устраняйте дубли
Проблема дублей не нова, но очень часто остается за рамками внимания вебмастеров и оптимизаторов. Однако она имеет большое значение для обеспечения качества поиска, о чем нам напоминают представители поисковых машин. Как можно увидеть из примеров, многие важные страницы сайтов не попадают в индекс и не приводят трафик или, наоборот, попадают в многократном размере и только засоряют его. В любом случае деньги, потраченные на продвижение такого сайта, расходуются нерационально. Обязательно проверьте ваш сайт на наличие дублей, устраните их доступными из перечисленных выше методами или закажите оптимизацию у специалистов (например в службе «Персональный менеджер»).
Партнёрская колонка

Что ждет вас на мероприятии
11 августа: препати
В первый день конференции участники выедут на море и смогут совместить приятное с полезным: пообщаться со спикерами в кулуарах и просто здорово отдохнуть. Именно так завязываются дружеские и деловые отношения.
Количество мест на препати ограничено.
12 августа: день докладов
Второй день пройдет в конференц-залах гостиницы «Radisson Калининград», где в трех потоках будет представлено по 10 докладов:
1. Интернет-маркетинг для бизнеса.
Как делать продажи через интернет и превращать посетителей в клиентов. Как увеличить в разы отдачу от присутствия бизнеса в сети.
2. Аналитика и исследования.
Эффективные методики поискового продвижения, кейсы и практические исследования. Секция для SEO-оптимизаторов.
3. Заработок в интернете.
Как больше заработать в Интернете. Секция для вебмастеров и манимейкеров – только начинающих или уже опытных.
Каждый докладчик прошел строгий отбор, каждый доклад отвечает трем принципам:
- практическая польза;
- доказанная эффективность;
- готовая методика для внедрения.
Компанию SeoPult представит Евгений Костин, который выступит в секции «Интернет-маркетинг для бизнеса» с докладом о «Широкомасштабном продвижении сайтов».
По окончании мероприятия всех участников ждет веселое афтепати с квестом «Казино»!
Укажите промокод SEOPULT и получите скидку 3000 рублей от полной стоимости билета.
До встречи на Baltic Digital Days!
Подробнее
Бесплатная онлайн-конференция “WebPromoExperts SEO Day” объединяет лучших специалистов СНГ и зарубежного рынка, которые поделятся массой полезной информации о последних SEO-тенденциях, нововведениях, изменениях и трендах.
В конференции примут участие докладчики от Google, Яндекс, Devaka.ru, Seoprofy, Netpeak, TRINET, Searchengines.ru, WebPromo, WebPromoExperts и другие.
Подробнее
Новости Обучающего Центра

На семинаре разбираются вопросы, касающиеся организации сайта, источников информации и работы исполнителей, а также производится подробный анализ кейсов.
Практикум предусматривает подробный разбор вопросов, связанных с таргетингом и его видами. Также речь пойдет об аукционах, источниках целевой аудитории, секретах баннеров, оптимизации рекламных кампаний, пост-кликах аналитики, инструментах и возможностях современного таргетинга.
Базовый курс — для начинающих в SEO. Идеален для маркетологов, специалистов по рекламе, а также владельцев сайтов и бизнесов. Курс дает информацию о принципах работы поисковых систем и предлагает практическое руководство по завоеванию топовых мест в поисковиках.
Новости поискового маркетинга

Ссылки по-прежнему важны для ранжирования в Google
Исследование аналитика Stone Temple Consulting Эрика Энджа подтверждает, что ссылки остаются критически значимым фактором ранжирования в Google. Аналогичное мнение высказывают и эксперты Moz и Searchmetrics, однако, по их мнению, фактор ранжирования начинает постепенно терять свою значимость. Что же касается Stone Temple Consulting, то их последнее исследование доказывает, что в настоящее время значимость ссылок гораздо выше, чем считалось ранее, и о снижении интереса к данному вопросу говорить не приходится. Анализ строился на основе коммерческих запросов с высокой конкуренцией, а также низкочастотных и информационных запросов.
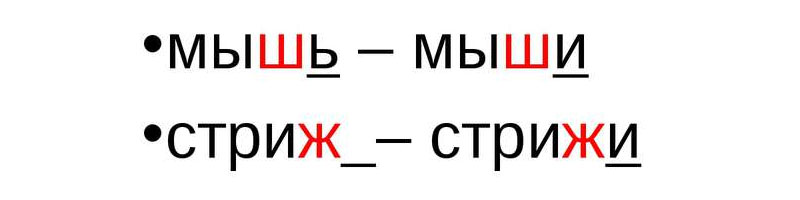
Единственное и множественное число слова – два различных ключевика
Единственное и множественное число одного и того же слова могут быть расценены поисковой системой Google как разные ключевые слова. Об этом сообщил представитель поиска Джон Мюллер. Важно также понимать, что правило работает не во всех случаях. Поэтому необходимо тщательно прорабатывать семантику, анализировать количество переходов из поиска по словоформам и продвигать свои ресурсы по наиболее эффективным запросам.

Сайт не потеряет позиций в Google, если конкуренты сообщат о спаме
Google заверил владельцев сайтов в том, что не стоит опасаться недобросовестных конкурентов, отправляющих отчеты о наличии спама на сторонних ресурсах. Все заявки проверяются вручную, уточнил сотрудник компании Джон Мюллер.
Смотрите на





Почитать на сладкое
- Реальные размеры России на карте мира;
- Средний возраст человека увеличится до 200 лет;