 |
Выпуск №64: Настройка robots.txt |
|
|
| |
 Новый докладчик от «Яндекса» на конференции CyberMarketing-2011!
7 октября в Москве на конференции CyberMarketing-2011 от «Яндекса» выступит Кирилл Николаев, руководитель группы в отделе веб-поиска. Поскольку мероприятие имеет практическую направленность, мы пригласили не человека из менеджмента, а специалиста, работающего над поиском «Яндекса».
Новый докладчик от «Яндекса» на конференции CyberMarketing-2011!
7 октября в Москве на конференции CyberMarketing-2011 от «Яндекса» выступит Кирилл Николаев, руководитель группы в отделе веб-поиска. Поскольку мероприятие имеет практическую направленность, мы пригласили не человека из менеджмента, а специалиста, работающего над поиском «Яндекса».
Тема доклада: «Ранжирование «коммерческих» запросов – вчера, сегодня, завтра»
Тезисы:
- SEO – причины возникновения, развитие, противодействие со стороны поисковых систем
- Отношение «Яндекса» к SEO – оптимизация vs накрутки
- Новый подход к ранжированию «коммерческих» запросов
|
Нечасто представители «Яндекса» откровенно обсуждают подобные темы, особенно в формате конференций, где любой желающий может задать вопрос – как во время доклада, так и в кулуарах.
Регистрируйтесь на конференцию на нашем сайте.
Внимание! В следующих выпусках рассылки организаторы и докладчики ответят на ваши вопросы по конференции – ждем ваших писем на pr@seopult.ru.
С уважением, Сергей Баиров, директор по маркетингу SeoPult.
|
|
| |
Новости Обучающего Центра CyberMarketing
|
|
| |
 Бесплатный обучающий курс по заработку в сети – составь программу на свой выбор!
Посещайте семинары Центра CyberMarketing в комплексе: вы можете организовать себе целый обучающий курс по заработку в сети, и к тому же – совершенно бесплатный!
Бесплатный обучающий курс по заработку в сети – составь программу на свой выбор!
Посещайте семинары Центра CyberMarketing в комплексе: вы можете организовать себе целый обучающий курс по заработку в сети, и к тому же – совершенно бесплатный!
Начать стоит с общей темы монетизации порталов и блогов – станет ясно, какому типу проекта отдать предпочтение. Последовательные базовый и продвинутый курсы SEO помогут вам поднять сайт в результатах поиска и начать привлекать на него ощутимый трафик. Со временем вы можете поключить к вашему сайту контекстную рекламу – неплохие результаты при монетизации блогов и «новостников» показывает технология одноцентового трафика.
А для достижения блестящих результатов в продвижении вашего сайта мы рекомендуем вам посетить семинар «SeoPult – всё о работе с Системой». Ведущий – руководитель техподдержки SeoPult Николай Коноплянников.
С уважением, Мария Трушкова, координатор Обучающего Центра CyberMarketing.
|
|
| |
Технологии поискового маркетинга
|
|
| |
 Настройка robots.txt
Настройка robots.txt
Защита информации на вашем сайте – один из залогов успеха бизнеса в сети. Утечка данных с сайта, особенно личных данных пользователей, крайне негативно скажется на репутации компании. Поэтому при поисковом продвижении сайта нужно думать не только о том, какие страницы сайта должны попасть в ТОП поисковых систем, но и о том, какие не должны быть проиндексированы ни при каких обстоятельствах. Основной инструмент ограничения доступности информации для поисковых роботов – файл robots.txt.
Файл robots.txt чаще всего используется для запрета индексирования поисковыми роботами страниц:
- с конфиденциальной информацией (интернет-магазины и любые сайты, хранящие личные данные пользователей);
- перемещённых или удалённых (например, при изменении структуры сайта или появления нового зеркала для максимально быстрого обновления кэша поисковой системы);
- дублей контента (блоги, интернет-магазины, сайты с использованием пейджинга и др.)
Отметим, что современные CMS имеют встроенные возможности запрета индексирования дублирующих страниц по виду URL, так что использовать для этого robots.txt вам вряд ли придётся.
Robots.txt также позволяет задавать поисковому роботу время загрузки страниц и другие технические характеристики вашего сайта, однако использование таких директив имеет свои особенности в каждой конкретной поисковой системе и в сущности не является приоритетной задачей файла robots.txt.
Что такое robots.txt
Текстовый файл robots.txt согласно общепринятому стандарту располагается «в корне» сайта и всегда открыт для чтения – в первую очередь, как следует из названия, роботам поисковых систем. Однако вы свободно можете открыть robots.txt любого сайта с помощью своего браузера. Посмотрим, например, файл сайа skype.com, просто дописав в адресной строке на главной странице «robots.txt» после слэша:
– и нажав Enter:
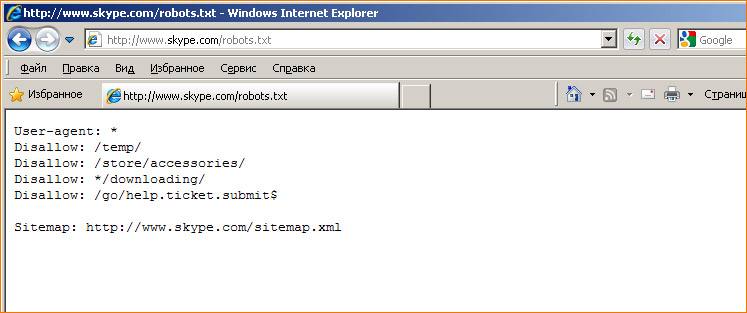
На открывшейся странице мы видим настройки индексирования данного сайта для поисковых роботов. О синтаксисе и назначении директив мы подробно расскажем далее. Кстати, в отдельных случаях неправильное использование директив в robots.txt помогает сразу диагностировать имеющиеся проблемы с индексированием сайта.
Обратите внимание, что крупные сайты практически не используют в robots.txt никаких других директив, кроме Disallow, однозначно воспринимаемой поисковым роботом любой популярной системы.
Robots.txt: историческая справка
Стандарт для robots.txt никому не принадлежит, а начало его использования приходится на 1994 год. Сейчас robots.txt используется всеми популярными поисковыми системами. Файл robots.txt – это The Robots Exclusion Protocol, то есть файл исключений для поисковых роботов. Robots.txt противоположен по смыслу файлу sitemap.xml: robots.txt ограничивает поисковым роботам обход сайта, а sitemap.xml наоборот – указывает файлы для индексирования. При этом robots.txt первичен – прежде, чем поисковый робот начинает загружать какие-либо страницы сайта, он обращается именно к файлу robots.txt, поэтому основной директивой файла robots.txt является директива запрета индексирования – Disallow.
Основные базы знаний по использованию robots.txt – это сайт www.robotstxt.org (на английском языке) и robotstxt.org.ru.
Кто виноват?
Наличие файла robots.txt в структуре сайта не обязательно. Отсутствие явно заданного через robots.txt запрета воспринимается поисковым роботом как разрешение загружать любое доступное содержимое сайта. Если сайт ведёт работу с конфиденциальными данными, доступ к которым возможен без авторизации (так делать нельзя ни при каких обстоятельствах), SEO-специалистам и вебмастерам следует заранее позаботиться об ограничении попадания этой информации в открытый доступ: нужно составить список страниц сайта, которые ни в коем случае не должны попасть в индекс поисковых систем, и запретить индексирование этих страниц в файле robots.txt.
Не стоит обвинять поисковых роботов в том, что в индекс поисковых систем попадают, например, номера телефонов, адреса, паспортные данные или непубличные документы, как это было в скандалах с операторами сотовой связи, государственными учреждениями, интернет-магазинами и так далее: эта ситуация говорит как раз о хорошей работе поисковых роботов.
Важно понимать, что если на страницу с конфиденциальной информацией невозможно попасть одним или несколькими переходами с главной страницы сайта, это не значит, что страница «спрятана» от поискового робота: ссылка на страницу может быть кем-то размещена и на сторонних ресурсах – тогда страница с большой вероятностью окажется в индексе поисковой системы. Существуют также многочисленные причины попадания страниц в индекс, не связанные напрямую с человеческим фактором, то есть действующие автоматически: RSS-каналы, агрегаторы контента и другие (подробно эти причины были описаны на странице блога «Яндекс.Поиска»: «Почему всё находится»). Поэтому SEO-специалист должен всегда напрямую запрещать поисковой системе обходить страницы с «секретной» информацией, если эта проблема не была решена на этапе проектирования сайта.
Синтаксис в robots.txt
Обратимся теперь к оформлению файла robots.txt. В отличие от HTML-документов или XML-карт, в robots.txt содержатся непосредственно директивы для поисковых систем без каких-либо дополнительных блоков информации, описывающих назначение файла – оно вытекает просто из названия.
Как мы говорили выше, основная используемая в robots.txt директива – Disallow. Поскольку в интернете существует далеко не одна поисковая система, то в общем случае вебмастер может задать запреты для всех поисковых роботов согласно принятом синтаксису, указав в строке после User-agent: символ ‘*’. Таким образом, самый простой запрет – это запрет индексирования всего сайта любыми поисковыми роботами. Выглядит он так:
|
User-agent: *
Disallow: /
|
Начиная со слеша можно указывать отдельные папки или файлы или маски для запрета индексирования, при этом часть файлов из этих папок можно открыть, выглядеть это будет так:
User-agent: Yandex
Allow: /cgi-bin
Disallow: /
|
– запрещает скачивать всё, кроме страниц, начинающихся с '/cgi-bin'.
Обратите внимание, что если для данной страницы сайта подходит несколько директив, то выбирается первая в порядке появления в выбранном User-agent блоке. Например, такая запись –
User-agent: Yandex
Disallow: /
Allow: /cgi-bin
|
– запрещает скачивать весь сайт
Спецсимволы в robots.txt
При указании путей директив Allow-Disallow можно использовать спецсимволы '*' и '$', задавая, определенные регулярные выражения. Символ ‘#’ отделяет комментарии к коду в файле robots.txt.
Спецсимвол '*' означает любую (в том числе пустую) последовательность символов. Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx' и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private', но и '/cgi-bin/private'
|
По умолчанию к концу каждого правила, описанного в robots.txt, приписывается '*', например:
User-agent: Yandex
Disallow: /cgi-bin* # блокирует доступ к страницам начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
|
Чтобы отменить '*' на конце правила, можно использовать спецсимвол '$', например:
User-agent: Yandex
Disallow: /example$ # запрещает '/example', но не запрещает '/example.html'
User-agent: Yandex
Disallow: /example # запрещает и '/example', и '/example.html'
User-agent: Yandex
Disallow: /example$ # запрещает только '/example'
Disallow: /example*$ # так же, как 'Disallow: /example' запрещает и /example.html и /example
|
Как видно из примеров, директивы можно сочетать друг с другом. Как правило, этого небольшого функционала достаточно для решения большинства вопросов с индексированием сайта, остальные директивы нуждаются в уточнении в рамках работы конкретной поисковой системы. Популярные поисковики предоставляют вебмастерам cправочную информацию по особенностям работы своих поисковых роботов – например, «Яндекс» и «Google».
Безопасность сайта и robots.txt
Поисковые роботы не могут добраться до страниц, доступ к которым возможен исключительно после авторизации, то есть с помощью обязательного ввода пароля. Это могут быть не только профили пользователей сайта, но и аккаунты администраторов. Таким образом, включать эти страницы в robots.txt не имеет смысла.
Будет разумно указать поисковым роботам не включать в индекс страницы с формой авторизации для пользователей сайта. Если же для администраторов сайта есть отдельная страница авторизации, на которую нельзя перейти с главной или внутренних страниц сайта, и эта страница имеет нестандартный вид URL, то сомнительно включать её в robots.txt под директивой Disallow. Помните о том, что опытный вебмастер всегда сможет обнаружить стандартную страницу авторизации для популярных CMS, а в индекс системы могут попасть страницы, ссылки на которых есть на уже проиндексированных страницах других сайтов.
Процитируем также страницы помощи Google о поисковом роботе Googlebot:
|
«Хотя Google не сканирует и не индексирует содержание страниц, заблокированных в файле robots.txt, URL-адреса, обнаруженные на других страницах в Интернете, по-прежнему могут добавляться в индекс. В результате URL страницы, а также другие общедоступные сведения, например текст ссылок на сайт или заголовок из каталога Open Directory Project, могут появиться в результатах поиска Google».
|
Таким образом, хотя в индекс поисковой системы может не попасть содержимое страниц, могут попасть их URL, что, в общем-то, не является гарантией того, что конфиденциальные данные не попадут в руки злоумшыленников.
SEO-специалист должен составить список страниц, которые совершенно точно не должны попасть в открытый доступ в интернете, однако поскольку список этих страниц будет находиться в открытом для всех файле robots.txt, злоумышленникам не придётся даже искать страницы с «той самой» секретной информацией, о чём прямо сказано на сайте robotstxt.org: «Файл robots.txt виден всем. Не пытайтесь использовать этот файл для того, чтобы спрятать информацию».
Кроме того, не все роботы соблюдают общепринятые стандарты для robots.txt. А также robots.txt может использоваться специально написанными программами, цель которых – поиск уязвимостей ваших веб-серверов.
Эти вещи всегда нужно иметь в виду, если вы заботитесь о безопасности данных на вашем сайте.
Использование robots.txt в мошеннических целях
Файл robots.txt можно использовать и с целью нанести ущерб сайту. Всегда будьте в курсе того, кто имеет доступ к вашему сайту. С помощью robots.txt можно добиться понижения позиций сайта вплоть до полного выпадения его из индекса. Приведём некоторые примеры таких манипуляций.
- Директива Disallow может использоваться для запрета индексирования отдельных папок (разделов сайта). Обратите внимание на имена этих папок: кроме разделов со служебной информацией там могут оказаться и разделы с контентом.
- Директива Crawl-delay отвечает за временной промежуток в секундах между последовательной загрузкой страниц сайта и используется при больших нагрузках на вебсервер. Увеличение временного промежутка может привести к тому, что поисковый робот будет индексировать сайт слишком долго.
Как мы говорили в самом начале нашей рассылки, такие манипуляции с robots.txt легко определить даже не вникая в структуру сайта – просто открыв файл robots.txt в браузере.
Noindex, nofollow
В связи с файлом robots.txt нельзя не упомянуть микроформаты noindex и nofollow.
Значение nofollow атрибута rel тега <a> (запрет передачи веса по ссылке) входит в спецификацию HTML, и на данный момент соблюдается всеми популярными поисковыми системами.
Тег noindex был предложен компанией «Яндекс». Этот парный тег предназначен для запрета индексирования части содержимого на странице, например так:
...
<noindex>Текст или код, который нужно исключить из индексации Яндекс</noindex>
...
|
На данный момент тег noindex используется только Яндексом. Более того, поскольку тег noindex не входит в официальную спецификацию языка HTML, то большинство HTML-валидаторов считает его ошибкой. Потому для того, чтобы сделать код с noindex валидным рекомендуется использовать тот факт, что noindex не чувствителен к вложенности и это позволяет использовать следующую конструкцию:
|
<!--noindex-->Текст или код, который нужно исключить из индексации Яндекс<!--/noindex-->
|
Возможно использование noindex в качестве мета-тега на конкретной странице (например, /page.html):
<html>
<head>
<meta name="robots" content="noindex" />
<title>Эта страница не будет проиндексирована</title>
</head>
...
|
Приведённая выше запись аналогична следующей конструкции в robots.txt:
User-agent: Yandex
Disallow: /page.html
|
Что делать, если конфиденциальные данные с вашего сайта попали в открытый доступ
К сожалению, бывают неприятные ситуации, когда не все страницы с конфиденциальными данными были закрыты от индексации. Рано или поздно такие страницы попадают в сеть и распространяются по интернету, вызывая многочисленные скандалы, шумиху и нередко – судебные иски. Вебмастерам в этом случае следует придерживаться следующего порядка действий:
- Определите список страниц, которые необходимо закрыть от индексации. Выясните причину их попадания в открытый доступ: если эти страницы должны быть доступны только через форму авторизации, примите соответствующие меры в модулях вашей CMS.
- Добавьте список страниц в файл robots.txt с помощью директивы Disallow для всех поисковых роботов. Помните, что если информация появилась в индексе одной поисковой системе, то в течение короткого времени она появится в индексе как минимум всех популярных поисковых систем, а также может быть сохранена пользователями интернета.
- Обратитесь напрямую в поисковые системы для скорейшего удаления страниц из индекса, соответствующие формы есть у «Яндекса» и у «Google».
- Узнайте, была ли скопирована конфиденциальная информация с вашего сайта и выложена на сторонних ресурсах. Если это произошло, обратитесь к владельцам сайтов (модераторам) с просьбой об удалении контента. Вы также можете обратиться в техподдержку поисковых систем.
К сожалению, ответственность за распространение конфиденциальных данных лежит в первую очередь на плечах владельца сайта – источника утечки.
Выводы
Итак, сделаем некоторые основополагающие выводы об использовании файла robots.txt.
- Robots.txt нельзя использовать с целью скрыть какую-либо информацию: указывая страницы, которые следует игнорировать поисковым машинам, вы в любом случае сами сообщаете место, где на вашем сайте могут содержаться конфиденциальные данные.
- Не все поисковые роботы (не считая программ злоумышленников) соблюдают общепринятые стандарты, некоторые роботы имеют свои особенности. Занимаясь поисковой оптимизацией, SEO-специалист должен в первую очередь ориентироваться на все те поисковые системы, с которых на сайт приходит существенное количество трафика.
- Проектируйте свой сайт таким образом, чтобы свести использование robots.txt (и в особенности директивы Disallow) к минимуму. О безопасности информации следует подумать на самых ранних этапах создания сайта, чтобы впоследствии не пришлось «латать дыры».
- Если вы столкнулись с проблемой утечки данных со своего сайта в открытый доступ, немедленно запретите поисковым системам индексацию страниц с конфиденциальной информацией, а затем обратитесь в поисковую систему, чтобы максимально быстро исключить страницы из поиска.
- Размещайте ваши сайты на хорошем хостинге и не перегружайте страницы информацией, чтобы не пришлось указывать поисковым роботам технические указания о времени обхода страниц.
Заметим, что механизмы поисковых систем стремятся к такой организации, чтобы создать сайт было максимально просто, а вебмастерам не приходилось изучать особенности работы поисковых роботов. Тем не менее, на данный момент знать основы использования robots.txt принципиально важно при продвижении в первую очередь интернет-магазинов и других сайтов, содержащих конфиденциальную информацию, а также при смене структуры сайта или переезде сайта на новый домен.
|
|
|
| |
В ТОП без гирь: аудит сайта от Николая Евдокимова
|
|
| |

Здравствуйте, Николай.
Просим Вас дать рекомендации по нашему сайту www.friendlytoys.ru.
Проблем с ним вагон и маленькая тележка. Рекламный бюджет на ссылки съедает практически всю прибыль. Наших сео продвиженцев уволили в марте, походив на семинары в кибермаркетинге.
Сайт работает без малого 2 года, по позициям динамика отрицательная. Товар не уникальный у нас, но цены очень низкие, явно можем больше продавать, но яндекс нас упорно не любит.
Сейчас начали работать над уникальностью карточек товара, пытаемся защитить их от копировпния, как на семинаре учили. Однако яндекс не обращает никакого внииания на то, что мы прописываем в карточки товара (meta discription, title etc), все выдает в поиск всякую нерелевантную чепуху. Как пример новых карточек можно посмотреть автотреки по вторым тачкам 62238 и62239.
Будем благодарны за любые комментарии по сайту и его продвижению через Сеопульт.
С уважением, Михаил и Дарья.
|
Аудит сайта читайте в нашем блоге.
Ваши заявки на аудит контекстной рекламы и SEO-аудит присылайте на pr@seopult.ru.
|
|
| |
Новости поискового маркетинга
|
|
| |
 Новые рекламные возможности «Яндекса»
Новые рекламные возможности «Яндекса»
«Яндекс.Директ» порадовал тремя обновлениями, самое значительное из которых – возможность переноса рекламной кампании из Google AdWords с помощью CSV-файла. Два других обновления касаются расширения настроек кампании и более плотной интеграции «Яндекс.Метрики» в интерфейс «Яндекс.Директа» – теперь можно указать до 5 счётчиков в рамках одной кампании.
Комментарий SeoPult
«Яндекс» старается максимально увеличить число рекламодателей – пользователей «Яндекс.Директа» и привлечь к себе сторонников Google AdWords, ведь контекстная реклама – это основа заработка поисковых систем. Более точный таргетинг благодаря улучшенной интеграции «Яндекс.Метрики» позволит рекламодателям сэкономить. Совместимость с Google AdWords облегчит создание рекламных кампаний и рекламодателям из-за рубежа, что может привлечь новые средства для развития всех технологий «Яндекса».
|
Google AdWords раскрыл тайну ТОПа
Теперь рекламодатели могут узнать ориентировочную цену клика для объявлений, находящихся в самом верху страницы, над естественной выдачей Google, а также в рекламном блоке справа. Вместе с облегчением оценки рекламного бюджета Google начал относиться лояльнее к новым объявлениям, показ которых был приостановлен – теперь они проходят модерацию так же, как и «активные» объявления – в общей очереди.
Комментарий SeoPult
Эта возможность Google Adwords позволит готовить рекламные кампании к запуску заранее и не ждать лишний раз одобрения модератора – вероятно, Google уже начал готовиться к ажиотажу с покупками к новому году и рождеству, когда конкуренция среди рекламодателей возрастает многократно.
|
Поиск Google: PDF и PageRank
Мэтт Каттс в очередном видеообращении дал понять вебмастерам, что грамотная внутренняя перелинковка действительно помогает поднять значение PageRank, однако не так высоко, как этого можно добиться с помощью внешних ссылок на сайт. Основным фактором улучшения показателя Мэтт назвал качество контента. Качество содержимого является основой для высокого ранжирования не только HTML-страниц, но и PDF-документов – Google умеет индексировать текст в таких документах благодаря OCR-алгоритмам и не отдает предпочтения при формировании выдачи какому-то определённому виду документов, будь то HTML, DOC, TXT или какой-то другой индексируемый формат.
Комментарий SeoPult
Google даёт понять, что продвигать можно не только сайты, но и любые другие индексируемые документы. Основное значение, как и прежде, имеют ссылки, однако плохой контент не удастся вывести в ТОП в любом случае.
|
|
|
| |
Ответы на вопросы
|
|
| |
 Вопрос: Я много времени потратил на оптимизацию сайта и внутреннюю перелинковку, но результаты от продвижения меня не устраивают. Думаю о том, чтобы начать закупать ссылки, но не знаю, как покупать хорошие и думаю, что нецелесообразно покупать слишком дорогие ссылки – можно ли как-то настроить закупку ссылок в SeoPult по их стоимости?
Вопрос: Я много времени потратил на оптимизацию сайта и внутреннюю перелинковку, но результаты от продвижения меня не устраивают. Думаю о том, чтобы начать закупать ссылки, но не знаю, как покупать хорошие и думаю, что нецелесообразно покупать слишком дорогие ссылки – можно ли как-то настроить закупку ссылок в SeoPult по их стоимости?
Ответ: Если вы не работали раньше с Системой, мы рекомендуем начать продвижение сначала в простом режиме – так вы познакомитесь с интерфейсом и поймёте, как действует механизм закупки ссылок и формируются ссылочные бюджеты. От простого интерфейса уже можно будет перейти к профессиональному – в таком режиме вы можете настроить фильтры на ограничение максимальной цены за ссылку.
Вопрос: Я продвигаю свой блог и зарабатываю на продаже рекламы с него. Что лучше использовать – продвижение по нескольким ключевым словам с помощью SEO или одноцентовый трафик? Что выйдет дешевле?
Ответ: Максимального эффекта для продвижения сайта можно добиться сочетанием средств PPC и SEO (вы может завести такой комплексный проект в SeoPult), однако всё зависит от тематики вашего блога, от конкуренции по выбранным вами ключевым словам и от того, какой именно способ монетизации блога вы выбрали.
|
|
| |
|
|
| |
|
|
|
|
|
|
 Новый докладчик от «Яндекса» на конференции CyberMarketing-2011!
7 октября в Москве на конференции CyberMarketing-2011 от «Яндекса» выступит Кирилл Николаев, руководитель группы в отделе веб-поиска. Поскольку мероприятие имеет практическую направленность, мы пригласили не человека из менеджмента, а специалиста, работающего над поиском «Яндекса».
Новый докладчик от «Яндекса» на конференции CyberMarketing-2011!
7 октября в Москве на конференции CyberMarketing-2011 от «Яндекса» выступит Кирилл Николаев, руководитель группы в отделе веб-поиска. Поскольку мероприятие имеет практическую направленность, мы пригласили не человека из менеджмента, а специалиста, работающего над поиском «Яндекса».
 Бесплатный обучающий курс по заработку в сети – составь программу на свой выбор!
Посещайте семинары Центра CyberMarketing в комплексе: вы можете организовать себе целый обучающий курс по заработку в сети, и к тому же – совершенно бесплатный!
Бесплатный обучающий курс по заработку в сети – составь программу на свой выбор!
Посещайте семинары Центра CyberMarketing в комплексе: вы можете организовать себе целый обучающий курс по заработку в сети, и к тому же – совершенно бесплатный!
 Настройка robots.txt
Настройка robots.txt



 Новые рекламные возможности «Яндекса»
Новые рекламные возможности «Яндекса»
 Вопрос: Я много времени потратил на оптимизацию сайта и внутреннюю перелинковку, но результаты от продвижения меня не устраивают. Думаю о том, чтобы начать закупать ссылки, но не знаю, как покупать хорошие и думаю, что нецелесообразно покупать слишком дорогие ссылки – можно ли как-то настроить закупку ссылок в SeoPult по их стоимости?
Вопрос: Я много времени потратил на оптимизацию сайта и внутреннюю перелинковку, но результаты от продвижения меня не устраивают. Думаю о том, чтобы начать закупать ссылки, но не знаю, как покупать хорошие и думаю, что нецелесообразно покупать слишком дорогие ссылки – можно ли как-то настроить закупку ссылок в SeoPult по их стоимости?